cpu 和 kernal
本文最初是我想了解 epoll 的原理,然后顺着资料了解 I/O 模型,引发出同步、异步、阻塞、非阻塞的概念,然后就是系统调用,用户态和内核态,管道,进程等等概念,最后简单了解下 CPU 的工作原理等。 简单记录下,因为在看别的资料时,很多地方提起了这些概念,也没必要深入了解,纯粹是满足我的好奇心。
CPU
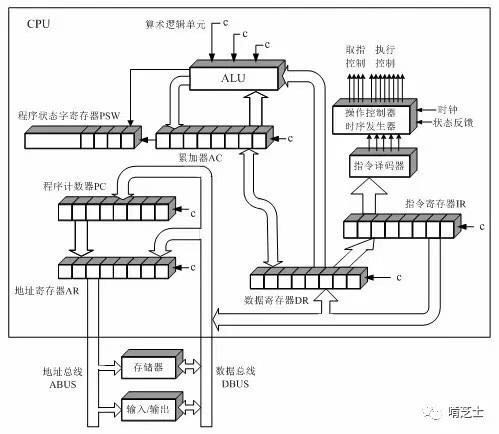 寄存器是 CPU 内部的元件
寄存器是 CPU 内部的元件
- 控制器
- 程序计数器(PC)保存下一条指令的地址
- 指令寄存器(IR)保存一条指令
- 指令译码器(ID)
- 时序发生器
- 操作控制器
- 运算器 接受控制器的命令,负责完成对操作数据的加工任务
- 算数逻辑单元(ALU)
- 累加寄存器(AC)
- 数据寄存器(DR)为 CPU 和主存、外设之间信息传输的中转站,用以弥补 CPU 和主存、外设之间操作速度上的差异
- 程序状态字寄存器(PSW) 记录当前运算的状态及程序的工作方式,以及中断和系统工作状态等信息,以便 CPU 和系统及时了解机器运行状态和程序运行状态。
指令从内存取到 DR,然后再放到 IR,然后交给 ID 来转换指令,再向操作系统发出对应的信号。 一条汇编指令大概执行过程是(不是绝对的,不同平台有差异):取指(取指令)、译码(把指令转换成微指令)、取数(读内存里的操作数)、计算(各种计算的过程,ALU 负责)、写回(将计算结果写回内存),有些平台里,前两步会合并成一步,某些指令也不会有取数或者回写的过程。
数据通过内存-Cache-寄存器,Cache 缓存是为了弥补 CPU 与内存之间速度差异设置的部件。
时钟频率
时钟相当于一个乐队的指挥 or 节拍器。大家都按一个速度来才是音乐,不然只能是噪声。(乐队成员 寄存器,乐队 CPU) 而时钟频率相当于这个速度。时钟频率用每秒时钟周期来度量。
Cache
位于内存和 CPU 之间容量较小速度很高的存储器,如果没有 Cache,每次 CPU 都需要找内存要数据,延迟估计在 80 个时钟周期。添加了 Cache 之后,L1 Cache 延迟在 4 个周期左右,L2 Cache 在 15 个周期左右,L3 在 50 个周期左右,由于添加了多级 Cahce,访问内存大概需要 120 个周期左右。CPU 需要的内容,90%在 L1 Cache 里面, 6% 在 L2 Cache 里面,%3 在 L3 Cache 里面,整个存储体系的延迟就在 7.2 个时钟周期。
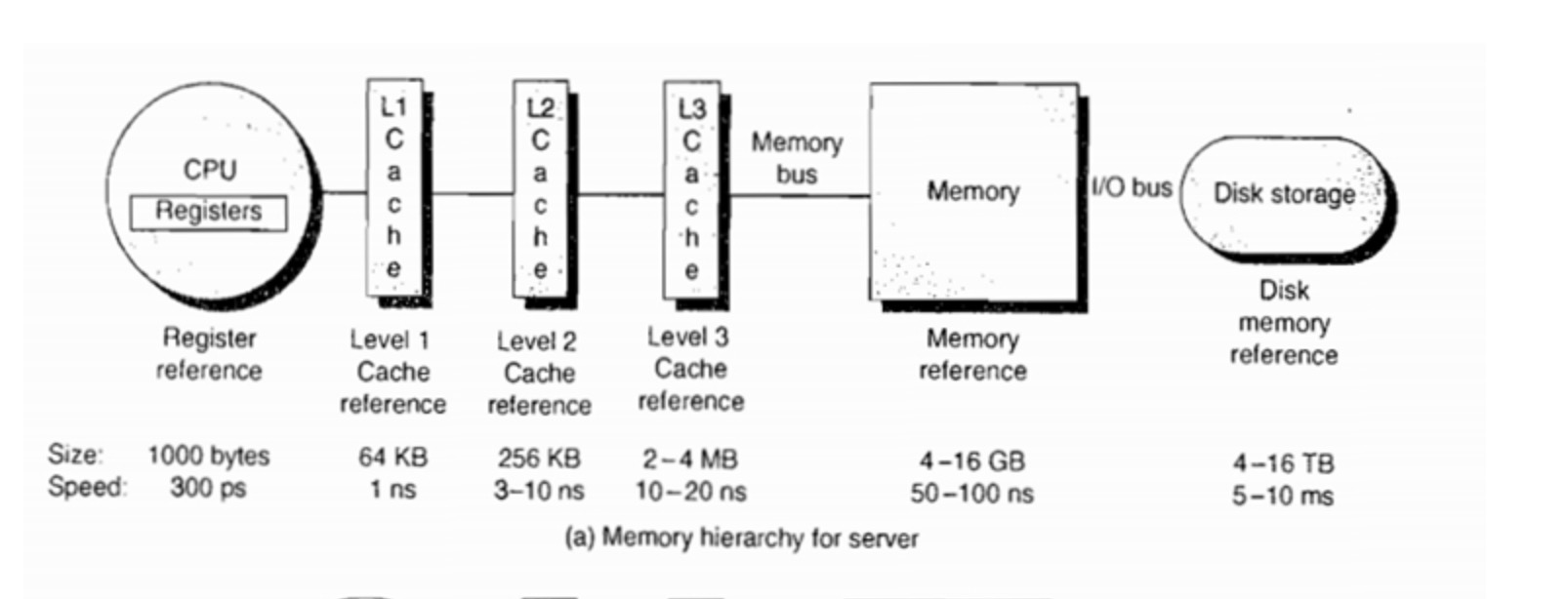
汇编指令通常有如下执行过程(参考 10),取指令->译码(指令转换成微指令)->取数(读内存的操作数)->计算(各种计算过程,ALU 负责)->写回(将计算结果写回内存)。 CPU 的主频,每个操作对应一个时钟周期,每个指令的执行成本不同(占用的时钟周期个数不同)。
中断
中断(英语:Interrupt)是指处理器接收到来自硬件或软件的信号,提示发生了某个事件,应该被注意,这种情况就称为中断。 通常,在接收到来自外围硬件(相对于中央处理器和内存)的异步信号,或来自软件的同步信号之后,处理器将会进行相应的硬件/软件处理。发出这样的信号称为进行中断请求(interrupt request,IRQ)。 如果没有中断,处理器向设备发出指令之后,需要反复轮询该设备是否完成了动作并返回结果,这就造成了大量处理器周期被浪费。引入中断以后,当处理器发出设备请求后就可以立即返回以处理其他任务,而当设备完成动作后,发送中断信号给处理器,后者就可以再回过头获取处理结果。
CPU 每个指令周期去查看中断寄存器,如果中断寄存器有效,也就是发生了中断,此时保存上下文,并跳转到中断 ISR 去处理。如果这种理解是对的,那么是否可以这么说:中断的本质其实就是轮询,只是比直接在代码中轮询的效率高,反应快?
常见问题
IO 请求无需 CPU 的参与?
计算机硬件上使用 DMA 来访问磁盘等 IO,也就是请求发出后,CPU 就不再管了,直到 DMA 处理器完成任务,再通过中断告诉 CPU 完成了。所以,单独的一个 IO 时间,对 CPU 的占用是很少的,阻塞了就更不会占用 CPU 了,因为程序都不继续运行了,CPU 时间交给其它线程和进程了。虽然 IO 不会占用大量的 CPU 时间,但是非常频繁的 IO 还是会非常浪费 CPU 时间的,所以面对大量 IO 的任务,有时候是需要算法来合并 IO,或者通过 cache 来缓解 IO 压力的。
计算机如何识别内存地址
计算机不需要识别内存地址。 你可以想象成为,内存里面有许许多多的闸刀,当你输入一个地址,他就会自动改变电信号,扳动内存里面的闸刀,使得其中一些导线可以被使用。 计算机只是提前连接好了所有的线路,你可以直接想象你输入地址就是扳动了内存里面的开关,让里面的的一部分数据可以使用。(就和扳动开关那一家的灯就能使用的原理是一样的)
内存
内存地址从 0 开始,每次增加 1,这种线性增加的存储器地址称为线性地址(linear address)。
RAM 内存的存储单元采用了随机读取存储器(RAM Random Access Memory),存储器的读取时间和数据与所在的位置无关。 RAM 被分隔成两个不同的区域- user space 和 kernal space。
- user space,用户进程使用的内存区域,不能直接访问 kernal space,可以通过 syscall 来访问 kernal space。
- kernal space 可以执行任意命令,调用系统的一切资源。
内存分页
应用程序对物理地址一无所知,只能通过虚拟内存地址进行数据读写,如果物理地址与虚拟地址一一对应,那么光记录对应关系就远超过内存空间的大小,而且翻译速度也要足够快,所以这个表也必须记录在内存中。 所以需要对物理地址和虚拟地址进行分页,虚拟地址到物理地址的翻译由操作系统负责,对应关系记录在分页表中,每个进程会有一套虚拟内存地址,每个进程有一个分页表。
物理地址和进程空间都分隔成页,在页内的地址是连续的。
通过 getconf PAGE_SIZE 来获取分页大小,一般是 4096
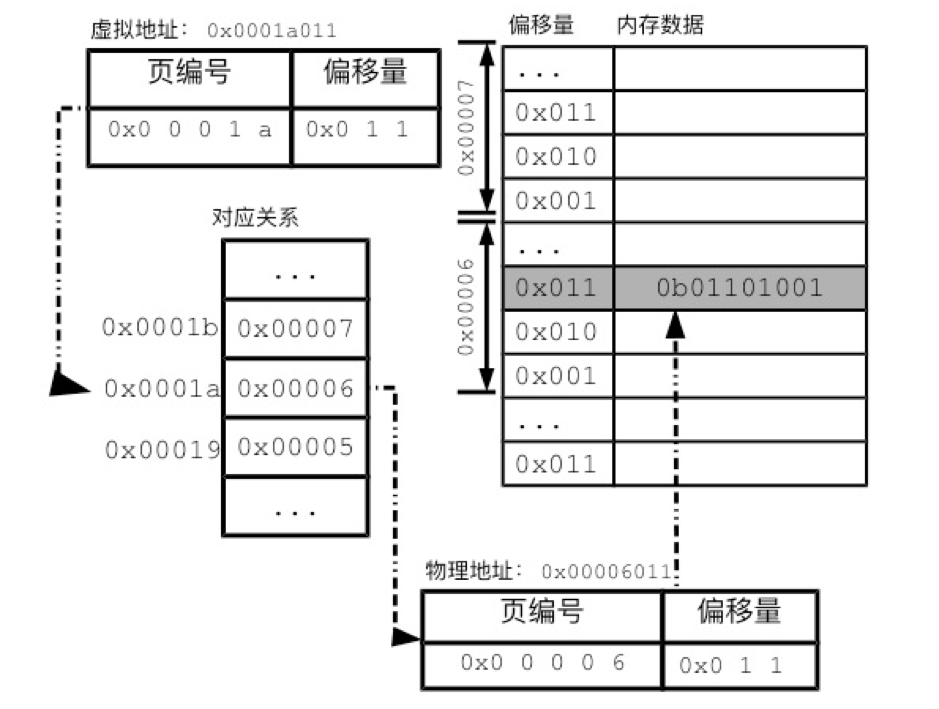 由上图地址翻译过程可以看出:
由上图地址翻译过程可以看出:
- 虚拟地址由页编号和偏移量组成
- 页编号可以找到分页表里面的与物理地址的对应关系
- 偏移量,由于页内地址是连续的,可以通过偏移量找到具体的物理地址
- 图上的示例是线性分页表,使用连续的地址来记录对应关系,实际应用一般都使用多级分页表
采用多级分页表来记录虚拟地址和物理地址对应关系,有两方面好处
- 多层分页表无需使用连续空间来记录对应关系
- 页编号分为一级编号和二级编号(对应一级表和二级表),如果一级编号对应的内存中的数据都为空,说明一级编号开头的地址中没有数据,那么二级表就不需要存在,减少了分页表占用的空间
内存分配
通过 malloc 分配的内存是连续的,堆内存的分配在逻辑地址上是连续的,但在物理地址上是不连续的(采用了内存分页),如果逻辑地址上没有连续的且足够大的空间,将分配失败。But please note that “malloc” is not a system call, it is provided by C library..
我们应用程序仅和逻辑地址打交道。当 fork 进程时,因为使用了 COW 优化,初始时父子进程是不同的逻辑地址,但对应的可能是相同的物理地址,只有子进程对内存有修改操作时,才会触发真正的内存拷贝。
int main()
{
int *p = (int *)malloc(sizeof(int) * 2);
p[0] = 89;
p[1] = 12;
// 可以看到分配的内存是连续的
// 0x7ff747c027f0 = 0x7ff747c027f0 => 0x7ff747c027f4
printf("%p => %p => %p \n", p, &p[0], &p[1]);
free(p);
// 将不使用的指针置 NULL 是一种保守做法。为了预防 dangling pointer bugs。内存空间被释放之后,如果之后被别的程序申请上了,可能会被 pointer 读取到。
// https://stackoverflow.com/questions/1025589/setting-variable-to-null-after-free
p = NULL;
return 0;
}
进程
开机的时候,内核创建一个 init 进程,其它进程都是通过 fork 来创建的,fork 是一个系统调用。每个进程在内存中有自己的一片空间。进程有一个 PID 之外,还有一个 PPID。进程会有一个进程树,可以通过 pstree 来查找,树的根节点就是 systemd
- 进程组的 leader 进程的 PID 称为进程组的 ID,领导进程可以先终结
# 进程ID 进程组ID 父进程ID 命令
[root@localhost ~]# ps -o pid,pgid,ppid,comm | cat
PID PGID PPID COMMAND
22097 22097 28085 ps
22098 22097 28085 cat
28085 28085 28015 bash
# 让命令在后台运行
ping localhost > log &
# 让命令后台运行
[root@localhost ~]# ping localhost > log &
# 2表示工作号 25071 表示PGID
[2] 25071
# 将 SIGTERM 信号发给 25071 进程组
[root@localhost ~]# kill -SIGTERM -25071
[root@localhost ~]# cat > log &
[3] 25884
[2] 已终止 ping localhost > log
# 让命令前台运行
[root@localhost ~]# fg %3
cat > log
# ctrl+z
^Z
[3]+ 已停止 cat > log
[root@localhost ~]# jobs
[1]- 已停止 ping localhost
[3]+ 已停止 cat > log
系统调用
系统调用是操作系统提供给用户进程调用的一组特殊接口。用户程序可以通过这组”特殊“的接口来获得操作系统内核提供的服务。可以通过 man 2 syscalls 来获取系统调用列表。系统调用和普通库函数调用很类似,只是系统调用由操作系统内核提供,运行与内核空间,而普通函数由函数库或者用户提供,运行与用户态。
系统调用主要分为如下几类:
- 进程控制
- 文件系统控制
- 系统控制
- 内存管理
- 网络管理
- socket 控制
- 用户管理
- 进程间通信
管道
cat test.txt | grep 'hello'
- fork 出一个子进程,并执行 exec 将 cat 载入内存
- 在 cat 程序中,用函数 pipe 定义出管道
- 定义出管道之后再调用 fork,生成一个子进程
- 父进程 cat 中关闭管道读端,将 cat 进程的标准输出重定向到管道的写段
- 子进程中将管道的写段关闭,将标准输入重定向到管道的读端,再调用 exce 将 grep 进程载入
- 最后,cat 的输出就是 grep 的输入了
管道是一种最基本的 IPC (Inter-Process Communication)机制,作用于有血缘关系的进程之间,完成数据传递。
- 本质是一个伪文件(实为内核缓冲区)
- 由两个文件描述符引用,一个表示读端,一个表示写端
- 规定数据从管道的写端流入管道,从读端流出
管道的读写行为:
- 读管道
- 管道有数据,read 返回实际读的字节数
- 管道无数据
- 写端关闭, read 返回 0(好像读到文件结尾)
- 写端没有完全关闭,read 阻塞等待
- 写管道
- 管道已满,write 阻塞
- 管道未满,write 将数据写入,返回实际写入字节数
局限性:
- 数据自己读不能自己写
- 数据一旦被读取,在管道中将不存在,不能被反复读取
- 由于管道采用半双工通信方式,数据只能在一个方向流动
- 只能在有公共祖先的进程间使用管道
如何创建和使用:
- 父进程调用
pipe函数(系统调用)创建管道,得到两个文件描述符 fd[0]、fd[1]指向管道的读端和写端 - 父进程调用 fork 创建子进程,那么子进程也有两个文件描述符指向同一管道
- 父进程关闭管道读端,子进程关闭管道写端。父进程向管道写入数据,子进程从管道中读取数据,进而实现进程间通信
应用
epoll
基础概念
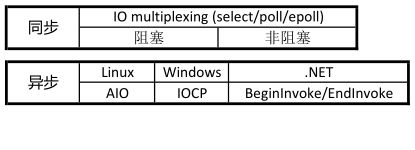
- 同步 发出调用时,在没有结果之前,调用不返回,需要主动读写数据,读写过程还是会阻塞。
- 异步 调用发生之后,直接返回,可以没有结果,比如 java 里面立即返回一个 future,可以在未来某个时候通过
future.get()来阻塞获取结果。异步只需要 I/O 完成的通知,并不需要主动读写数据,由操作系统完成数据的读写。 - 阻塞 调用结果返回之前,线程被挂起,调用线程只有得到结果之后才会返回
- 非阻塞 调用不能立即返回结果之前,该调用不会阻塞当前线程
几种 I/O 模型
- 阻塞 I/O 模型 默认所有套接字都是阻塞的,所以如果处理多个流。副作用:只能多进程(fork)或者多线程(pthread_create),但是这两种效率都不高
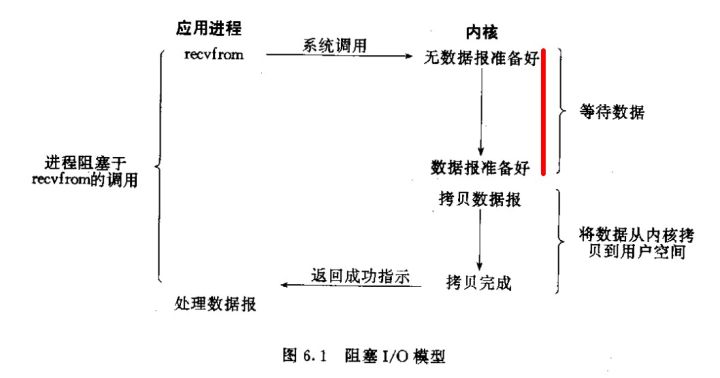
- 等待数据准备好
- 从内核向进程复制数据
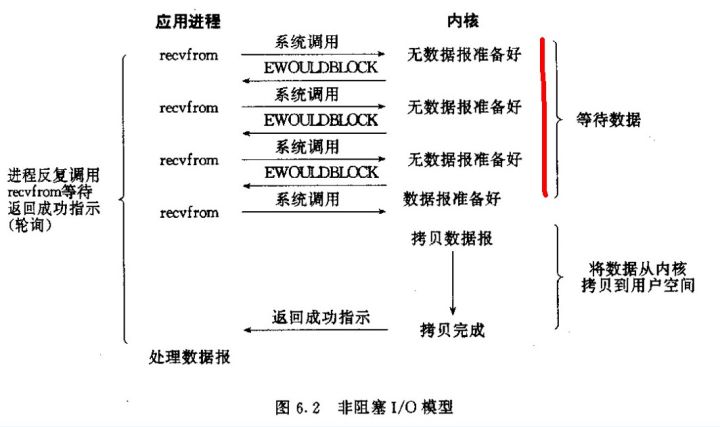
- 非阻塞 I/O,进程把套接字设置为非阻塞,所有的调用都是立即返回,无数据返回 EWOULDBLOCK,有数据返回数据。副作用:如果流中没有数据,会浪费 CPU 造成 CPU 空转。
I/O 多路复用,I/O 多路复用的阻塞是阻塞在 select/epoll 这样的系统调用上,而没有阻塞在真正的 I/O 系统调用如 recvform 上。复杂度是 O(k),k 为产生 I/O 时间的流的个数
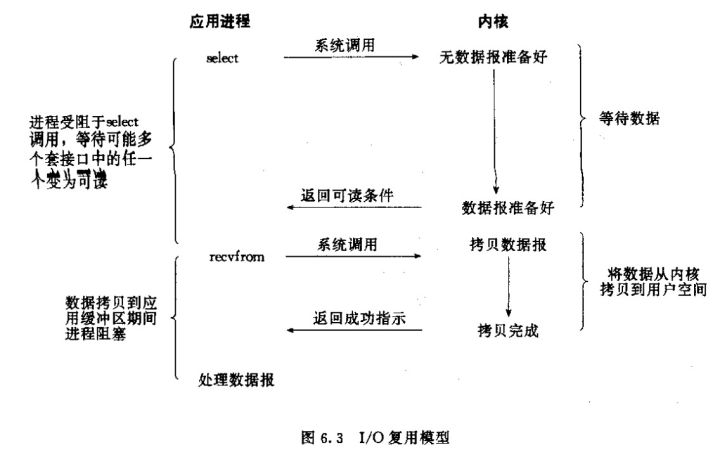
epoll_create创建 epoll 对象,一般epollfd = epoll_createepoll_ctlepoll_add/epoll_del 的合体,往 epoll 对象添加/删除某一个流的某一个事件- epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN); // 有缓冲区内有数据时 epoll_wait 返回
- epoll_ctl(epollfd, EPOLL_CTL_DEL, socket, EPOLLOUT); // 缓冲区可写入时 epoll_wait 返回
epoll_wait
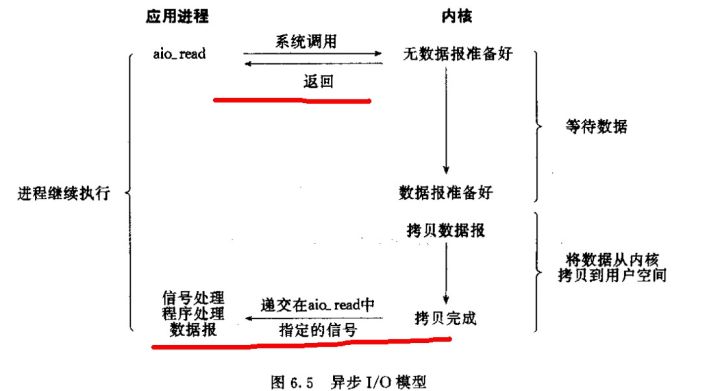
异步 I/O,告诉内核启动某个操作,并让内核在操作完成之后通知我们
reactor
很多高性能服务器都采用 reactor 模式,即 non-blocking IO + IO multiplexing。通常主线程只做 event-loop,通过 epoll_wait 等方式监听事件,而处理客户端请求在其它工作线程完成。
参考
8. epoll 或者 kqueue 的原理是什么? - 蓝形参的回答 - 知乎
9. 怎样理解阻塞非阻塞与同步异步的区别? - 大姚的回答 - 知乎